![]()
![]()
The profile complexity of a measurable unit is a combination of its content complexity and its context complexity. The content and context complexities should be independent of each other. The content complexity tries to measure the amount of information within a measurable unit (e.g., token or segment), while the context complexity tries to measure the location of a measurable unit within the source code. The CPG is designed such that the context complexity is the baseline complexity, with the content complexity riding on this baseline. The rationale of this design is to provide easy identification clusters, groups of contiguous segments of high complexity, which are based on the context. When a cluster is identified, the content complexity can be used to isolate the heavy segments in the cluster. With this design in mind, the range of magnitude of the context complexity should be larger than that of the content complexity. Currently, the content contribution is constrained to be between 0 and 3, while the context contribution is constrained to be between 0 and 15. The design provides the effect that the content complexity is a ripple riding on the curve of the context complexity.
The content metric measures the quantity of information in a unit, not the quality. The measurement on content quality would require semantic analysis of the code. An example of such semantic analysis is the reference to an identifier as a variable versus a function call or in discriminating between references to different variable identifiers based on the complexity of their underlying data types. Presently, the content quality is assumed to be constant across all measurable units. For example, references to Car_1 of type Real_Car and Car_2 of type Toy_Car will be treated the same (i.e., having the same token content complexity). Although type Real_Car may be much more complicated that type Toy_Car, the difficulty of creating and referencing an instance of either variable is the same from the viewpoint of a programmer. Hence the content complexities of the references to Car_1 and Car_2 are treated as being the same, while the context complexities of the declarations of their types, Real_Car and Toy_car, may be different.
Although the content complexity for most tokens is indeed held constant (i.e, 1.0), there are a few exceptions: left parenthesis, logical operators (e.g., and, or, not) and comparison operators (e.g., >, <, =). A left parenthesis normally indicates a compound expression, an index to an array or a parameter for a call to a procedure, a function or an entry. Thus a left parenthesis generally adds a level of detail to be further understood, thereby increasing complexity. Since a right parenthesis always corresponds to a left parenthesis, and generally marks the end of greater detail, thereby decreasing complexity, it is treated as a regular token. Also, a logical operator combines two conditions into one (except the operator not), so it is heuristically more error prone and complex. Comparison operators are treated similarly. Contributions for Ada 95 tokens are summarised below.
| Token Description | Symbol | Weight |
|---|---|---|
| Logical operators | and, or, not, ... | 1.5 |
| Comparison operators | <, >, =, <=, ... | 1.5 |
| Left parenthesis | ( | 1.3 |
| Identifiers | var1, proc1, ... | 1.0 |
| Others | +, -, *, /, ), var1, ... | 1.0 |
| Delimiters and punctuation such as the comma, semicolon, colon, etc. are not included. | ||
The content complexity, ![]() , of a CPG segment S is defined as the natural logarithm of the summation of all of its tokens' weight contributions.
, of a CPG segment S is defined as the natural logarithm of the summation of all of its tokens' weight contributions.
With this definition, the summation portion for most segments should be under 20, and the logarithm function will yield a value of less than 3.0.
The context complexity provides a baseline level of complexity for segments of simple statements nested within a compound statement, which itself may be nested several levels deep. The context complexity of a segment will be the summation of the complexities of all compound statements in which it resides. This means each compound statement contributes to the overall level of the complexity platform which is uniform for statements within it.
The complexity of a compound statement is based on three aspects: inherent complexity, reachability, and breadth. The inherent complexity, I, measures the difficulty and/or complexity nature of a compound statement. It is a subjective measurement. The rationale is that certain types of compound statements are more error prone than others. The inherent complexity weights in the table below have been used as a starting point.
| Compound Statement | Weight |
|---|---|
| SELECT, ACCEPT | 4 |
| CASE, IF, ELSE | 3 |
| WHILE | 3 |
| FOR, basic LOOP, EXIT | 2 |
| BLOCK | 1 |
| Others | 0 |
The reachability complexity, R, indicates the difficulty of reaching a statement with respect to its path predicate. The path predicate is expressed as a set of conditions, and hence R is defined as the sum of the individual Boolean condition complexities. The complexity of each Boolean conditional is calculated as the number of logical operators + 1. Although certain compound statements (e.g., ACCEPT) need an execution rendezvous to be reached, that is not considered in this complexity. Instead, it is included in the inherent complexity. Complexity R is used for the compound statement, such as WHILE, IF-THEN-ELSE and CASE-WHEN.
The Breadth complexity, B, represents the amount of computation involved in a compound statement and is approximated by the number of statements nested within the compound statements.
These three complexities are combined in the following way for a segment S within a compound statement Y.
with weighting coefficients ![]() = 1.0,
= 1.0, ![]() = 1.0 and
= 1.0 and ![]() = 0.1.
= 0.1.
Combining the content complexity, ![]() , and the context complexity,
, and the context complexity, ![]() , gives the profile metric,
, gives the profile metric, ![]() , for a segment. That is,
, for a segment. That is,
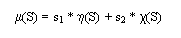
where scaling factors ![]() and
and ![]() are set to 1.0 for the examples. These scaling factors and the weighting coefficients from
are set to 1.0 for the examples. These scaling factors and the weighting coefficients from ![]() above provide a means for adjusting the impact that individual factors
have on the overall profile of the segment. To facilitate
experimentation and evaluation, GRASP provides a dialog box that allows
the user to manipulate the value of each scaling factor and weighting
coefficient.
above provide a means for adjusting the impact that individual factors
have on the overall profile of the segment. To facilitate
experimentation and evaluation, GRASP provides a dialog box that allows
the user to manipulate the value of each scaling factor and weighting
coefficient.
![]()